97. Разрушение программных систем
Сегодня я хочу поговорить о фундаментальном законе, которые разрушительно действует на все программные системы — энтропии.
На систему действует множество факторов, которые приводят к её деградации, разрушению и смерти. Именно из-за непонимания энтропии умирает большинство продуктов.

Она не очень интуитивна и требует глубокого анализа. Давайте для начала посмотрим, что разрушает продукты.
1. Технологический прогресс
Процессы и технологии создания софта непрерывно совершенствуются. Может быть, это не заметно на протяжении пары лет, но если окинуть взглядом 10–15 лет, то прогресс очевиден. Иногда он уходит в нежелательную для нас сторону, но он есть. Появляются новые языки программирования, новые платформы, библиотеки и подходы. Сейчас простейшее веб приложение можно собрать на коленке за пару часов. Раньше подобное дело требовало низкоуровневого программирования на C (кто-то еще не забыл CGI).
Постоянное усовершенствование технологий часто хоронит продукты, потому что новые конкуренты могут создавать решения в разы быстрее и качественнее, используя все модные и современные тренды (Slack vs. HipChat, Figma/Sketch vs. Adobe). Для сохранения динамики компании могут пытаться эволюционно внедрять новые технологии, но обычно это не дает преимуществ. Иногда помогает создание нового продукта с нуля. Это очень рискованная инициатива, которая мало чем отличается от стартапа со всеми вытекающими последствиями — вероятность провала около 90%.
2. Погоня за новым функционалом
Новые функции неизбежно увеличивают энтропию системы. Система становится сложнее, появляется больше точек разрушения. Больше фич — больше энтропии. Каждую фичу необходимо поддерживать, улучшать, стыковать с другими фичами.
Постоянное и быстрое добавление фич на протяжении всего жизненного цикла продукта — прямая дорога на кладбище. Если вся компания ориентирована на это, то старые фичи начинают деградировать, а новые не успевают стать отличными. Продукт находится в постоянном стрессе, пытается быть на острие, и вряд ли способен достичь баланса с точки зрения пользователей. Примеры таких продуктов: VersionOne и Targetprocess.
Я, например, каждый год проводил достаточно детальное сравнение количества выпущенных фич нашей компаний, и компаний конкурентов. И меня сильно удивляло, что мы выпускаем больше фич, чем JIRA. Я постоянно терял из виду, что JIRA развивалась за счет новых продуктов и полировки существующих фич и взаимодействий. Они улучшали текущие паттерны использования, а не добавляли новые. Мы многое делали правильно, но смещение баланса в новый функционал было моей ошибкой 2013 года.
Мне кажется, самые успешные продукты быстро наращивают функционал до определенной стадии, а потом практически останавливаются. Дальнейшие добавления существенно новой функциональности происходят медленно и очень аккуратно. После какой-то точки гораздо важнее правильная эволюция имеющейся функциональности, а не добавление новой. Хорошие примеры таких компаний: Basecamp, Facebook, JIRA.
3. Технический долг
С возрастом и развитием системы в ней неизбежно накапливаются нехорошие технические решения, странные паттерны, костыли и обходные тропинки. Архитектура системы теряет стройность под гнётом новых функциональных требований. Ключевые разработчики уходят из продукта. Знания теряются, и скорость деградации архитектуры увеличивается. Если ничего не делать, то вносить изменения в систему становится очень сложно. Даже фикс очень простого бага, вроде опечатки, может занять 30 минут.
Эта проблема хорошо известна, и у программистов есть в чемоданчике инструменты для починки примуса. Можно проводить рефакторинг, разбивать систему на модули и переписывать их, делать код ревью, удалять ненужный функционал. К сожалению, бравые менеджеры с флагами “Новые фичи” не дают инженерам возможности открыть чемоданчик. Я сам был таким менеджером. Ты живешь в постоянном ощущении отставания от конкурентов, их хочется догнать фичами. Но всё получается наоборот — фичи бумерангом бьют по системе.
Технический долг накапливается. Энтропия растёт. Причем скорость накопления долга возрастает нелинейно. Если первые пару лет проценты невелики, то потом они начинают расти достаточно быстро.
4. Изменение контекста и рынка
Рынки меняются (вплоть до исчезновения). Изменяются потребности пользователей, что требует изменения функционала и (внимание) новых фич. Если контекст меняется резко, а продукт уже довольно старый, то ему грозит быстрое вымирание. Если продукт молодой, без большого количества фич и технического долга, то у него еще есть шанс успеть за изменениями и адаптироваться.
Борьба с энтропией
В идеале продукт должен иметь:
- Глубокие структуры, которые улучшают гибкость, помогая справляться с изменением контекста и технологическим прогрессом.
- Процессы, направленные на постоянное исследование новых направлений и соблюдения баланса между новыми возможностями и улучшением старых возможностей.
Пройдемся коротко по методам:
Структуры
1. Модульная архитектура, изоляция отсеков переборками, вменяемые протоколы общения, правильная гранулярность модулей — и прочие лучшие практики, которые красиво звучат, но сложны в применении. Все они помогают изменять систему и вписать новые технологии, когда понадобится. Я специально не употребляю слово микросервисы, потому что не до конца верю в это направление. Мне кажется, микросервисы чем-то похожи на SAFe — это усложнённое решение. Мне лично пока больше нравится монолит с довольно большими сервисами-спутниками. Когда общение между сервисами станет очень дешевым и понятным, тогда можно увеличивать гранулярность.
 Раньше можно было доехать в Австралию на автомобиле… Зато сейчас там есть утконосы!
Раньше можно было доехать в Австралию на автомобиле… Зато сейчас там есть утконосы!
2. Повышение уровня абстракции. Это достигается генерализацией решений. К примеру, если вам в 5 мест системы нужно показать список сущностей, то UI компонент List можно сделать единым и везде использовать. Если вам нужно руками добавлять новые сущности в домен, то можно сделать домен гибким, чтобы сущности добавлялись пользователем по мере необходимости. Системы, реализованные на более высоком уровне абстракции, лучше выживают. Они могут быстрее реагировать на вариации контекста и дольше сохранять нужные качества при изменении рынка. Но их сложнее делать.
Процессы
1. Понимание жизненного цикла продукта, хороший баланс между новой функциональностью и улучшением текущей функциональности. Это уже лежит на хрупких плечах Product Owner’а. В целом для B2B продукта можно взять за основу правило 3–2. Три года делаем много новых фич и достигаем хорошей доли рынка, потому пару лет улучшаем текущие вещи и добавляем только стратегически важные новые вещи. Важное дополнение #1. Завоевание доли рынка и пользователей обычно происходит быстро. Важное дополнение #2. Если через 3 года у продукта все еще мало пользователей, то правило 3–2 лучше не применять. Скорее всего, нужно поискать радикальные пути изменения тренда, пивоты какие поделать, новые ниши глянуть. Нет смысла полировать продукт, который не особенно юзают.
2. Cпайки новых подходов и яйца, чтобы переписать всё с нуля. Несмотря на риск, такие попытки должны регулярно предприниматься малыми и очень опытными командами. Риск оправдывается тем, что финансовые потери невелики, а успех может быть значительным. Я вообще считаю, что в любом продукте rewrite is inevitable. Но обычно он случается либо от безысходности (а это уже слишком поздно и рискованно), либо от самоуверенного оптимизма (а это слишком бессистемно и глупо). Когда появляется возможность, продукт должен изобретаться заново. Такие постоянные эксперименты могут дать компании мощный источник новой информации и тот самый edge.
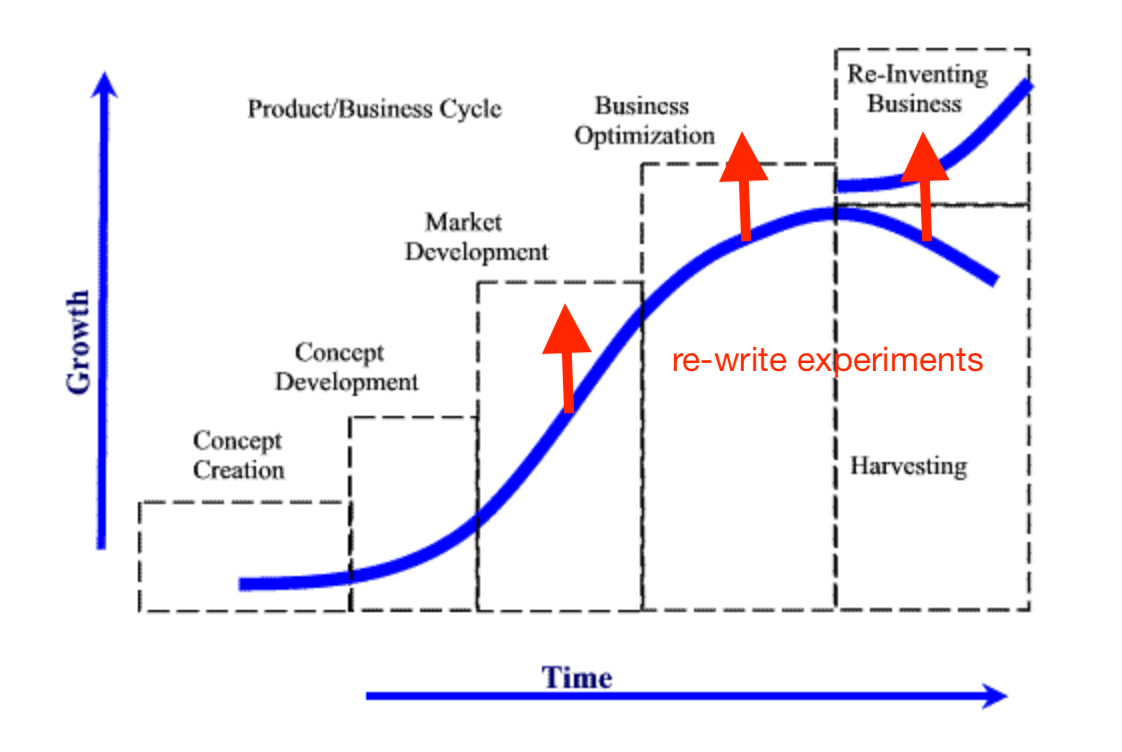 Re-write нужно делать практически всегда. Специально-ужасная картинка, чтобы потом все перерисовать (я забыл айпад взять с собой).
Re-write нужно делать практически всегда. Специально-ужасная картинка, чтобы потом все перерисовать (я забыл айпад взять с собой).
В конкретном случае Targetprocess у нас была первая версия в 2004, rewrite в 2006 и потом частичный rewrite в 2011–2013. Нам надо было его завершить. А после 2013 мы несколько лет потратили на новые фичи в старой технологической базе, спохватившись только во 2017.
3. Я скептически смотрю на правильный возврат технического долга. Скорее всего, этот процесс никогда не удастся наладить хорошо. Поэтому предыдущий пункт с постоянными экспериментами можно распространить и на модули. Проще переписывать плохие и устаревшие модули, чем пытаться всё время поддерживать их в хорошем состоянии. Модель прерывистого равновесия тут, скорее всего, работает лучше, чем непрерывное улучшение.
Бороться с энтропией сложно. Чтобы предотвратить разрушение любой системы, приходится тратить огромное количество сил. Чёрная королева была права.