Software Development: Fast and Slow.

Recently I read a fascinating book by Daniel Kahneman Thinking, Fast and Slow. It has tons of insights. Every chapter was a discovery. I learned so many new things.
I work in a software development company. It’s quite natural to apply new learned things to your domain. That’s what I’m doing in this post.
 One of the best books I’ve read in my life. Seriously.
One of the best books I’ve read in my life. Seriously.
System 1 and System 2
The book is about two systems in the human brain. System 1 is fast, intuitive, alert and cheap. System 2 is lazy, analytical and expensive. Most daily activities and tasks are solved by System 1, while the most complex tasks are redirected to System 2.
When you use System 1 you feel nothing. It’s natural and effortless. When you use System 2, you feel strain and pressure. You notice that you are really thinking hard. System 2 is effortful.
There are many experiments that proves existence of these two systems. Make no mistake, there is no clear separation of these systems on a physical brain structure, but they describe how people think and make decisions.
If you are a software engineer, you’ll immediately grasp the nature of System 1 and System 2. System 1 is quite similar to cache, while System 2 is a business layer. Cache is cheap and fast, business opearation is slow and expensive.
Now I’ll take first concepts from the book and find examples in software development.
What You See Is All There Is (WYSIATI)
People usually don’t think about things they don’t see (in a broad sense). If you have some information, it’s unlikely that you’ll immediately question it and go look for some alternatives. Quite often people make decisions based on existing facts and limited evidence. This leads to several biases:
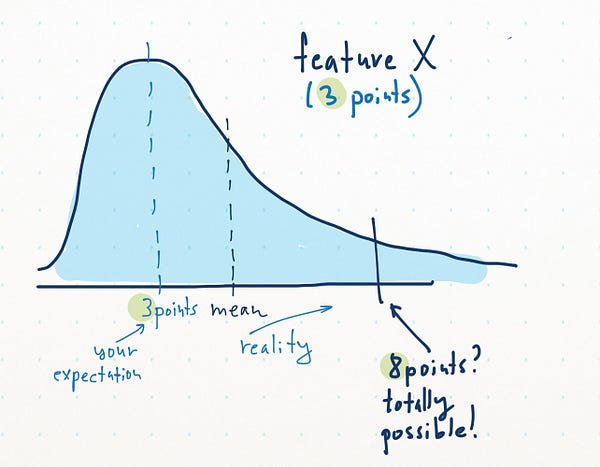 Estimation is not easy in software development. We make huge mistakes all the time. Estimation is a distribution.
Estimation is not easy in software development. We make huge mistakes all the time. Estimation is a distribution.
Overconfidence
Software estimation is the area where overconfidence flourishes. “We need twitter integration — you ask — We want to accumulate all tweets with specific tags. When you can complete this?” Developers often don’t ask additional questions and just provide quick estimate like, well, 2 days. This is System 1 in action. It’s extremely unlikely the answer is correct. Lack of information somehow doesn’t impede immediate estimate. Developers should be smart and confident, oh yes! But also they should escape WYSIATI and think carefully about unknowns.
Framing Effect
Problem wording does matter. If you describe the same problem using different words you can have different solutions or preferences. Consider two questions:
- “Do you think we need a very experienced developer to solve this simple problem?”
- “Do you think we need a very experienced developer to solve this complex problem?”
The question set the frame. It’s hard to answer “Yes” to the first question, it’s easy to answer “Yes” to the second one.
Base-rate Neglect
Some events are more likely than others. However, people have no good intuition about statistics.
Let’s say, you create a product that used by 1000 companies. You receive an email from a customer who think that his idea is really “must have” and should be implemented ASAP. The argumentation is perfect and does make real sense. You feel his pain and push this new feature to production with all your force. Well, you missed one thing: it may very well happen that 999 other customers have no need in this solution. You forget that customers base is large and a single request should be reviewed from that perspective.
It’s a very common mistake and I repeated it again and again myself. Now I know better and think very carefully about every request. No rush. In rush you delegate the decision to System 1, and this system do you no good in such a complex domain.
Answering an easier question
When we encounter a hard question, we tend to replace it in our mind with an easy one, that System 1 can handle. Here is an example.
You hear the question “How good will be progress on this project 3 months from now?” You replace this tricky question with “How good is progress right now?”
By doing this substitution, you don’t awake your lazy System 2 and allow System 1 to answer the easier question. We follow the path of least effort. The funny thing is that we don’t realize the substitution, we really think we answered the hard question!
Affect heuristic
If we like something or dislike something it affects our decisions greatly. For example, if you like node.js, you will be optimistic about choosing node.js for the new web application. If you hate node.js, you will provide so many arguments against it and will fight to death to apply another technology.
The affect heuristic is hard to overcome. People are not so rational, but clearly some reasonable comparison of technologies will be much better than a quick choice based on intuitive preferences.
I just scratches the surface, but it’s already obvious that our decisions in software development based on many biases and bad heuristics.
What can we do about it?
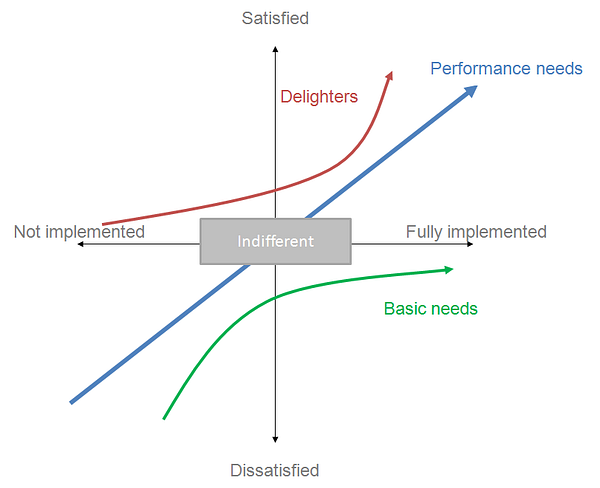 Kano Model is a good example. It helps to make more intelligent decisions about new features.
Kano Model is a good example. It helps to make more intelligent decisions about new features.
Intuition vs. Models
Kahneman was very skeptical about our abilities to wake up System 2 when it’s really needed. Indeed, how can we change a human nature?
However, it seems we can do something. We can apply models.
Model is almost always better than intuition. Even a very simple linear model is better than most (all?) experts in a domain. Model forces you to think about the domain, about various facets of the problem, look at it from different angles — use System 2.
Here is the simple question: What feature should we start next? You can rely on your intuition and say “Advanced Search”. It may happen that this feature is not so important and there are dozen of more important features. You can build a simple model and evaluate your backlog. For example, the model can have parameters like:
1. Kano model (basic, delighter, performance)
2. How many leads requested it
3. Competitors have it
4. How many customers requested it
5. Innovative, nobody has it
6. Effort (S, M, L, XL, …)
7. Complexity / Risk of failure
With this simple model you’ll make much better decision for sure.
I believe models can be applied to many areas in software development. Decision making and problem solving should rarely rely on intuition, unless you are Steve Jobs.